Custom LLMs without sharing compute
Running large language models (LLMs) on SaladCloud provides a convenient, cost-effective solution for deploying various applications without worrying about infrastructure. You can host your fine-tuned LLMs without sharing compute, protecting your data/prompts from being trained on.
Have questions about enterprise pricing for SaladCloud?
Book a 15 min call with our team.
Run popular models or bring your own

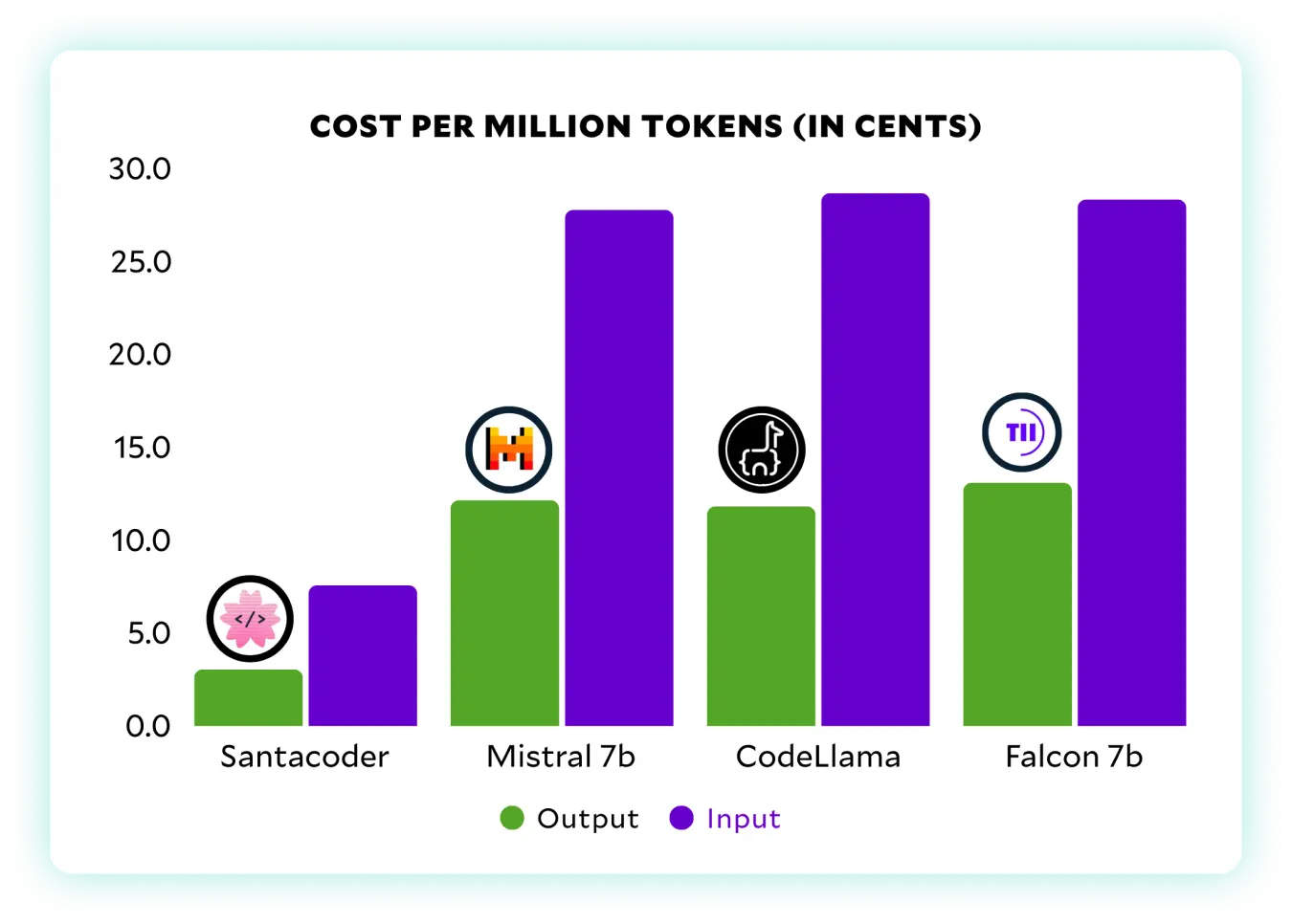
LLM Inference Hosting
As more LLMs are optimized to serve inference on GPUs with lower vRAM, SaladCloud’s network of RTX/GTX GPUs with the lowest GPU prices can save you thousands of dollars—offering enhanced efficiency and reduced costs.
Custom LLMs with UI
Deploy custom LLMs to thousands of GPUs at the lowest prices, scaling easily and affordably. Bring your models to life with a user-friendly UI like HuggingFace ChatUI.
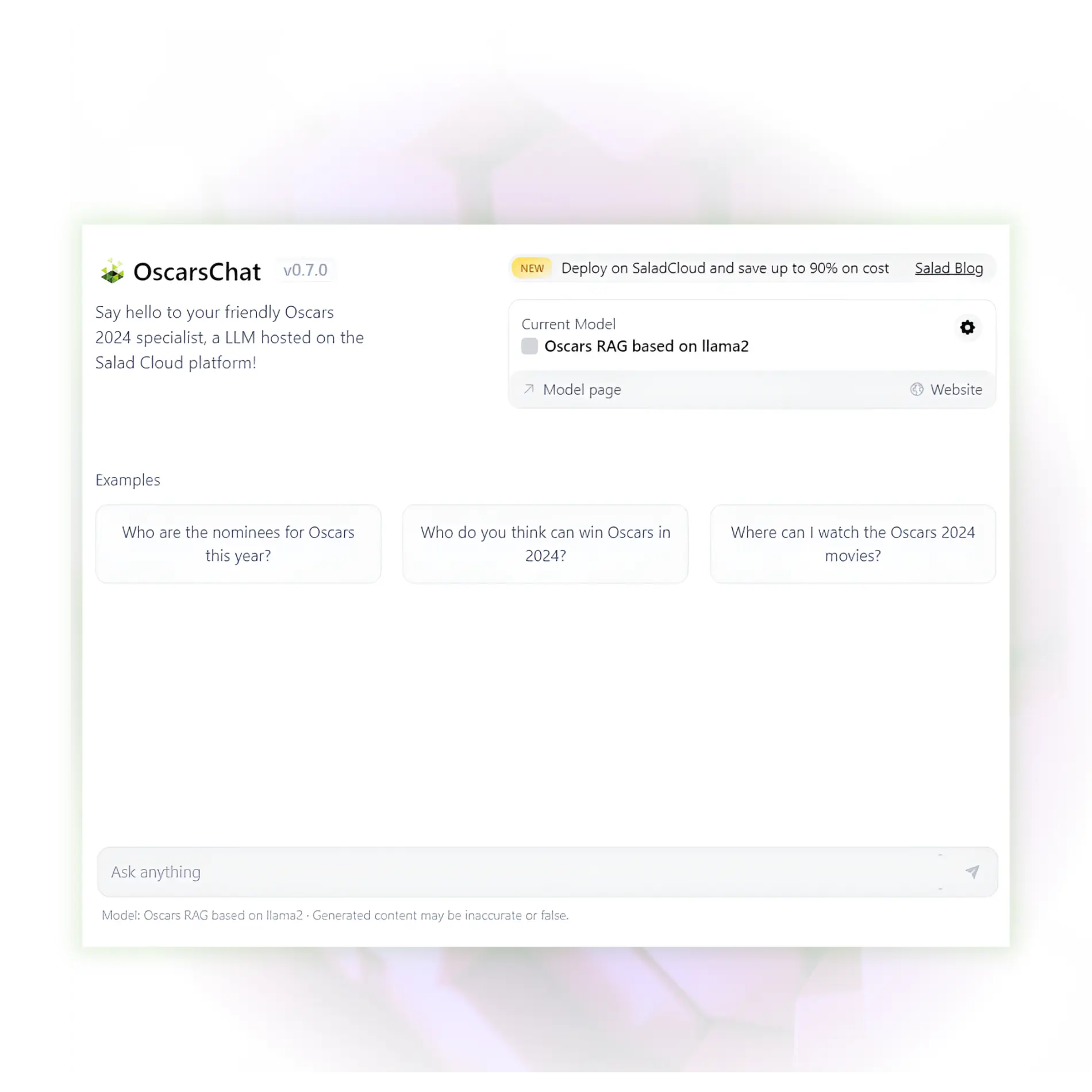
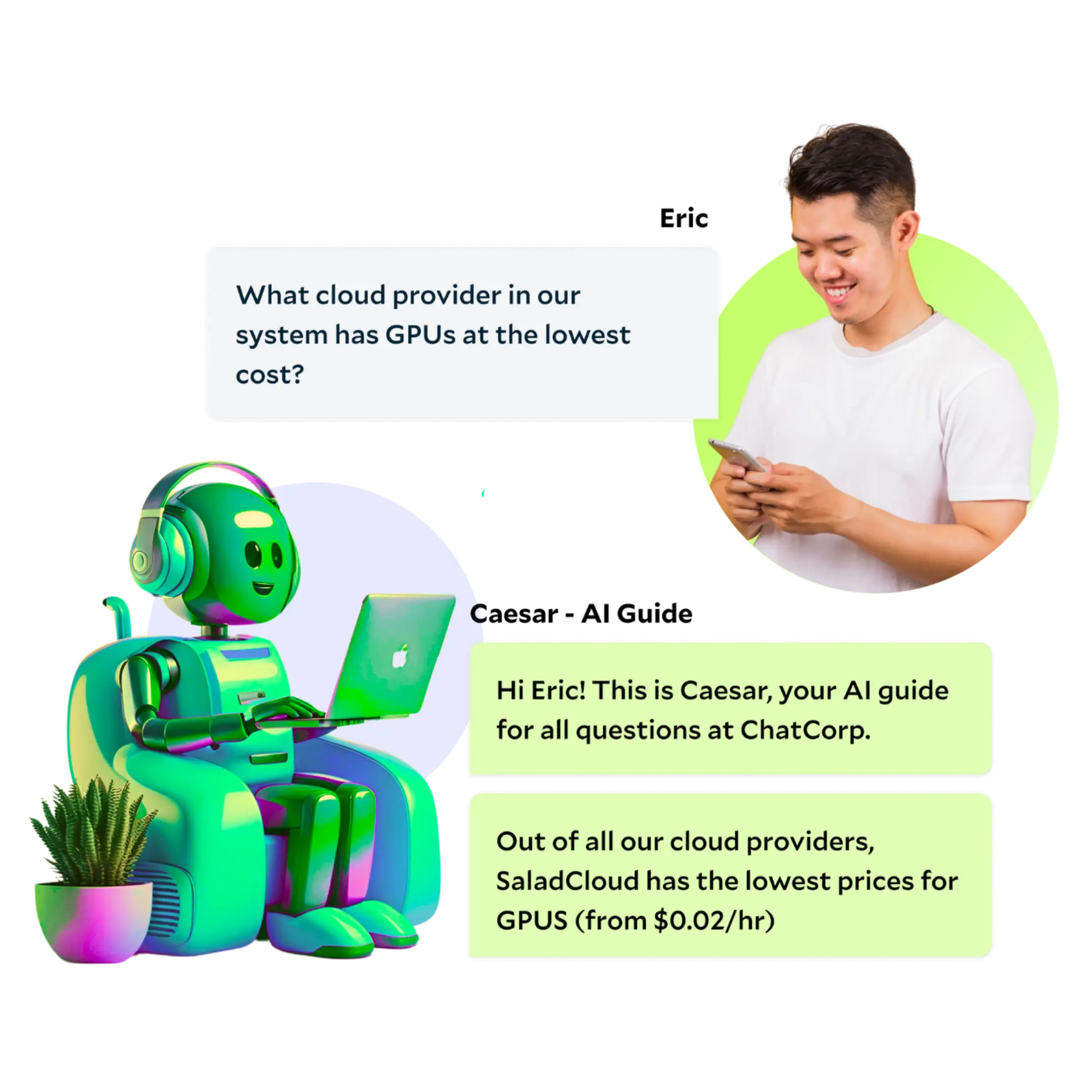
Enterprise Chatbots
Run your own Retriever-Augmented Generative (RAG) models with LangChain and Ollama to query your enterprise's data. Deploy/scale popular models in a customizable, cost-effective way with Text-Generation Inference (TGI).
Read our blog
Learn more about running Large Language Models (LLMs) on SaladCloud.


