Save up to 90% for
Voice AI inference
Whether you are serving inference for Speech-to-Text, Text-to-Speech, Chatbots, or batch translating 1000s of hrs of audio, Salad’s GPUs can reduce your cloud cost by up to 90% compared to managed services and APIs.
Get in touch with Sales for discounted pricing
Save even more for high-volume GPU use.







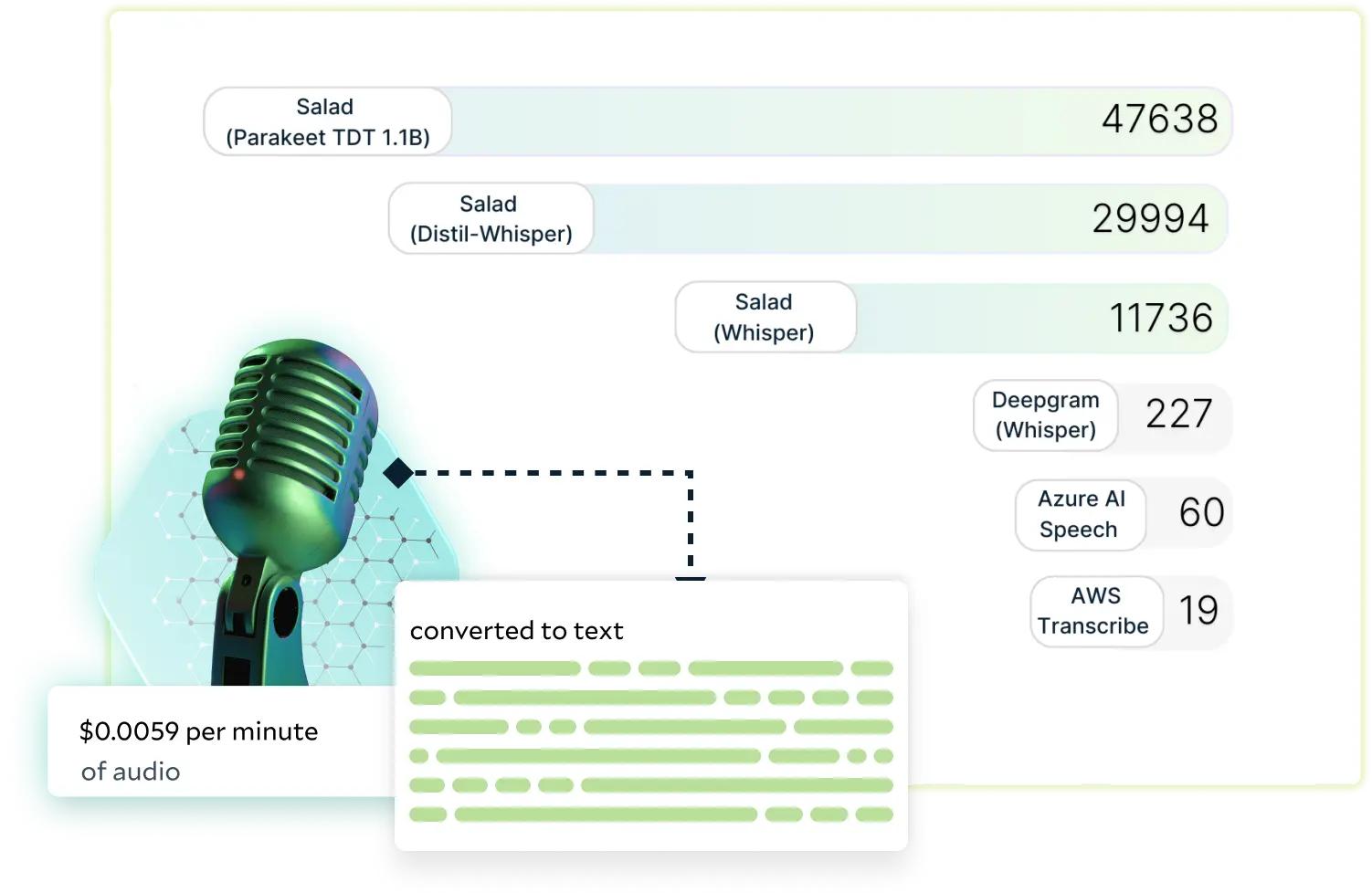
Speech-to-Text
For use cases like automatic speech recognition (ASR), translation, captioning, subtitling, etc., SaladCloud is 90% or more affordable than APIs and hyperscalers.
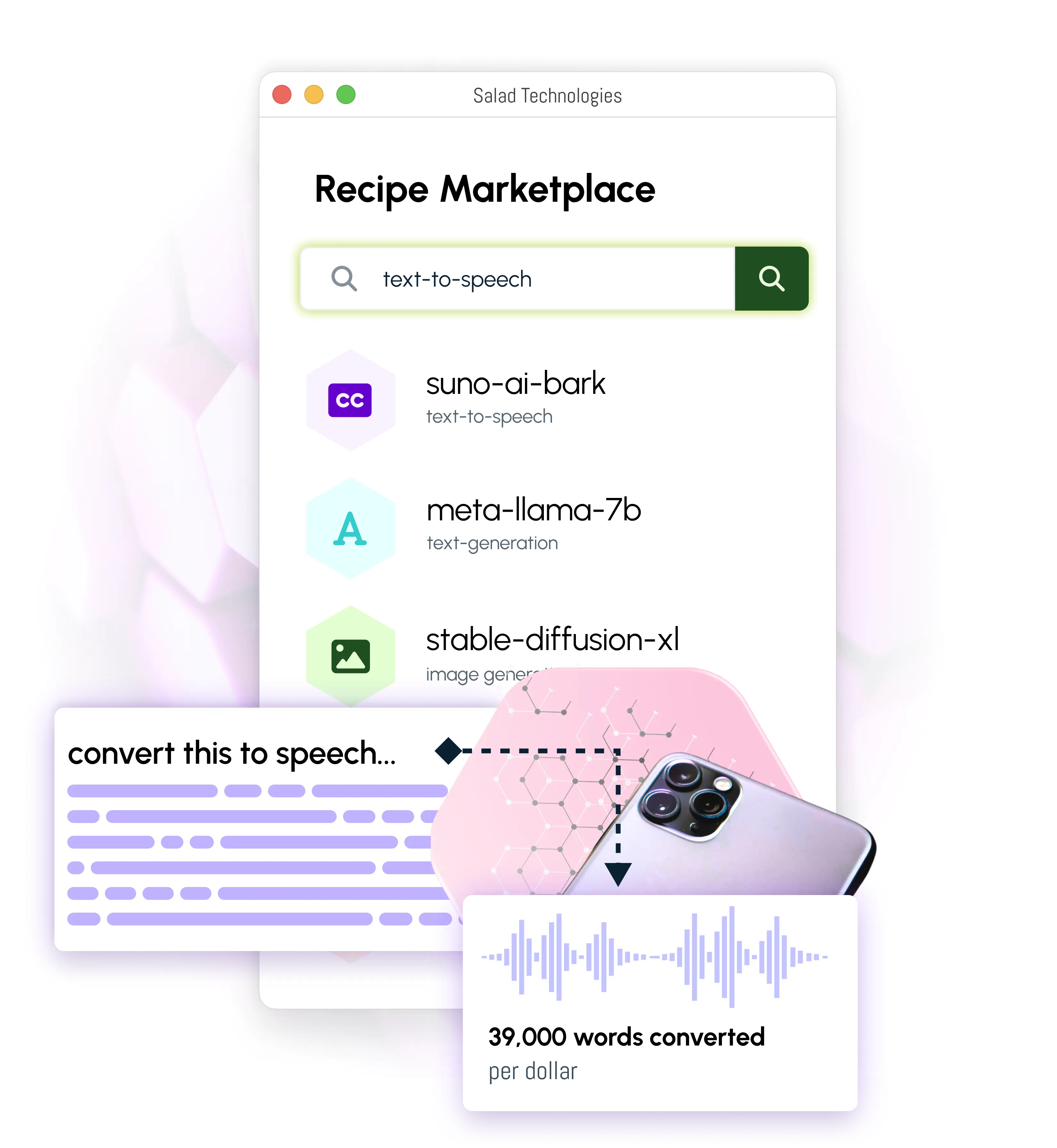
Text-to-Speech
Save up to 90% on Text-to-Speech (TTS) inference with SaladCloud’s consumer GPUs. The RTX & GTX series GPUs deliver the best cost performance for TTS inference.
The Lowest Cost For Voice AI Inference
Voice AI models are perfect for consumer GPUs. They offer incredible cost performance and save thousands of dollars compared to running on public clouds.
Scale quickly to thousands of GPU instances worldwide without the need to manage VMs or individual instances, all with a simple usage-based price structure.
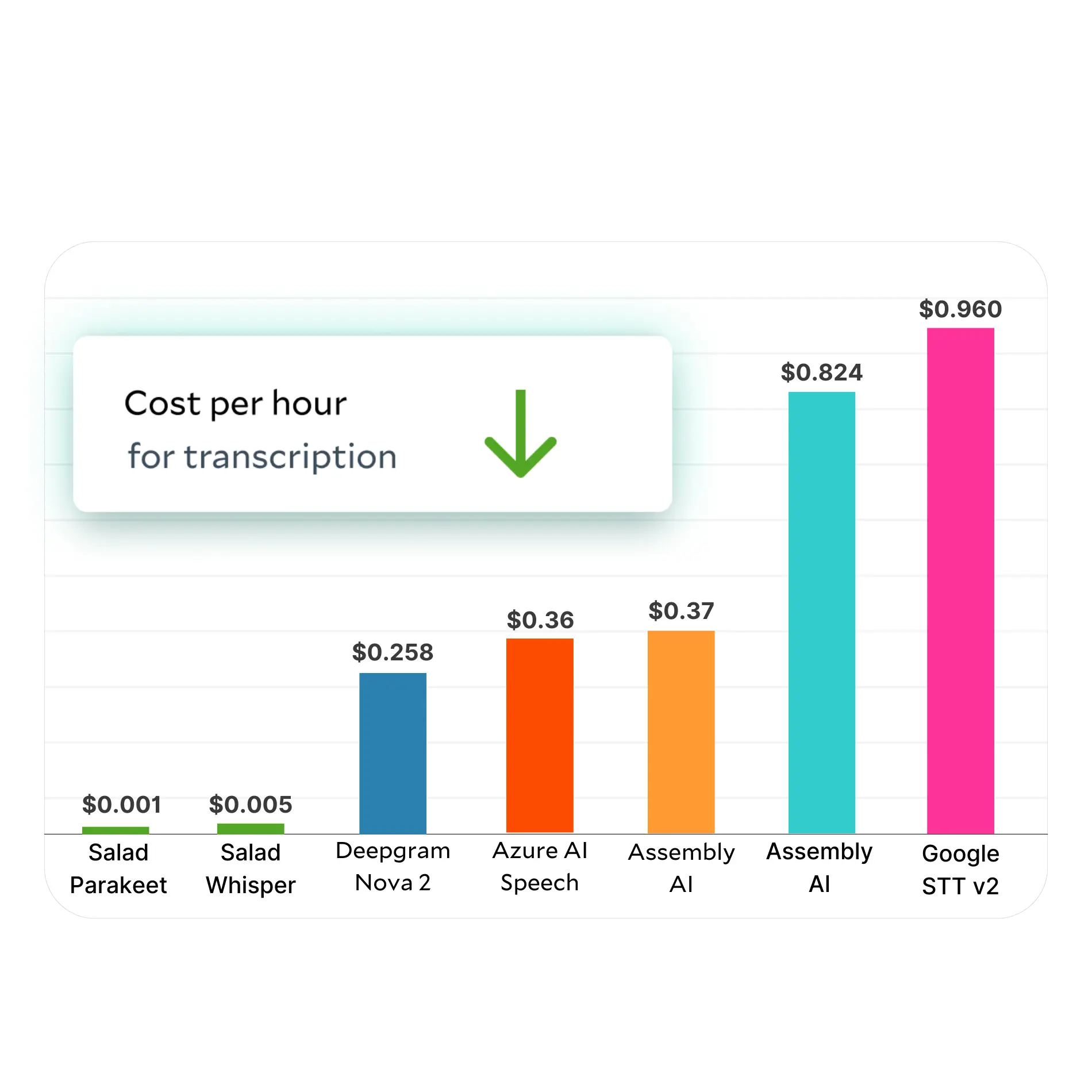
Transcription
Save up to 98% on transcription costs compared to the public cloud with about 60X real-time speed on RTX 3090s.
Translation
Get better machine translation economics on SaladCloud's network of GPUs at the lowest market prices.
Captioning / Subtitles
Cut AI captioning/subtitle generation costs by at least 50% on SaladCloud.