








Text-to-Image
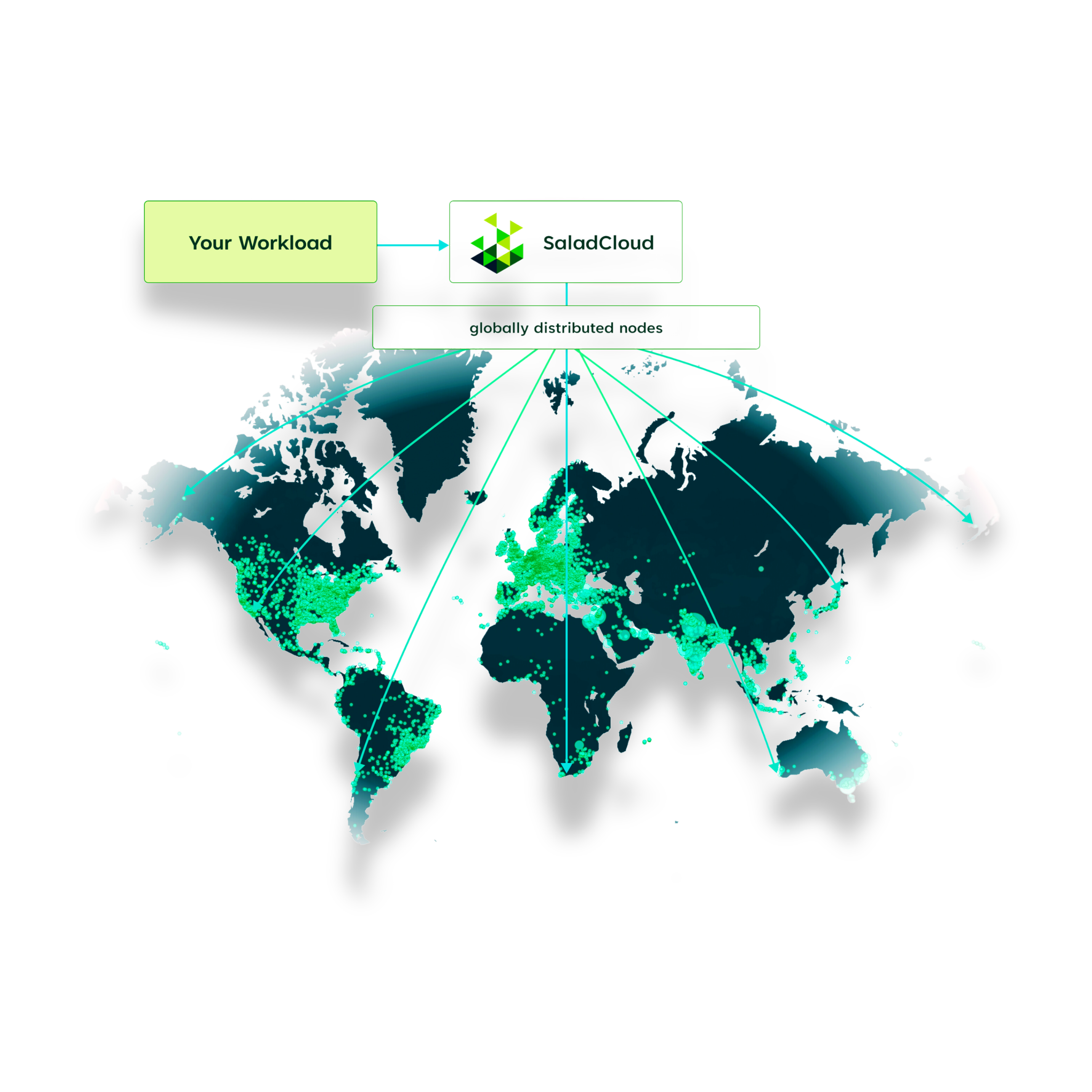
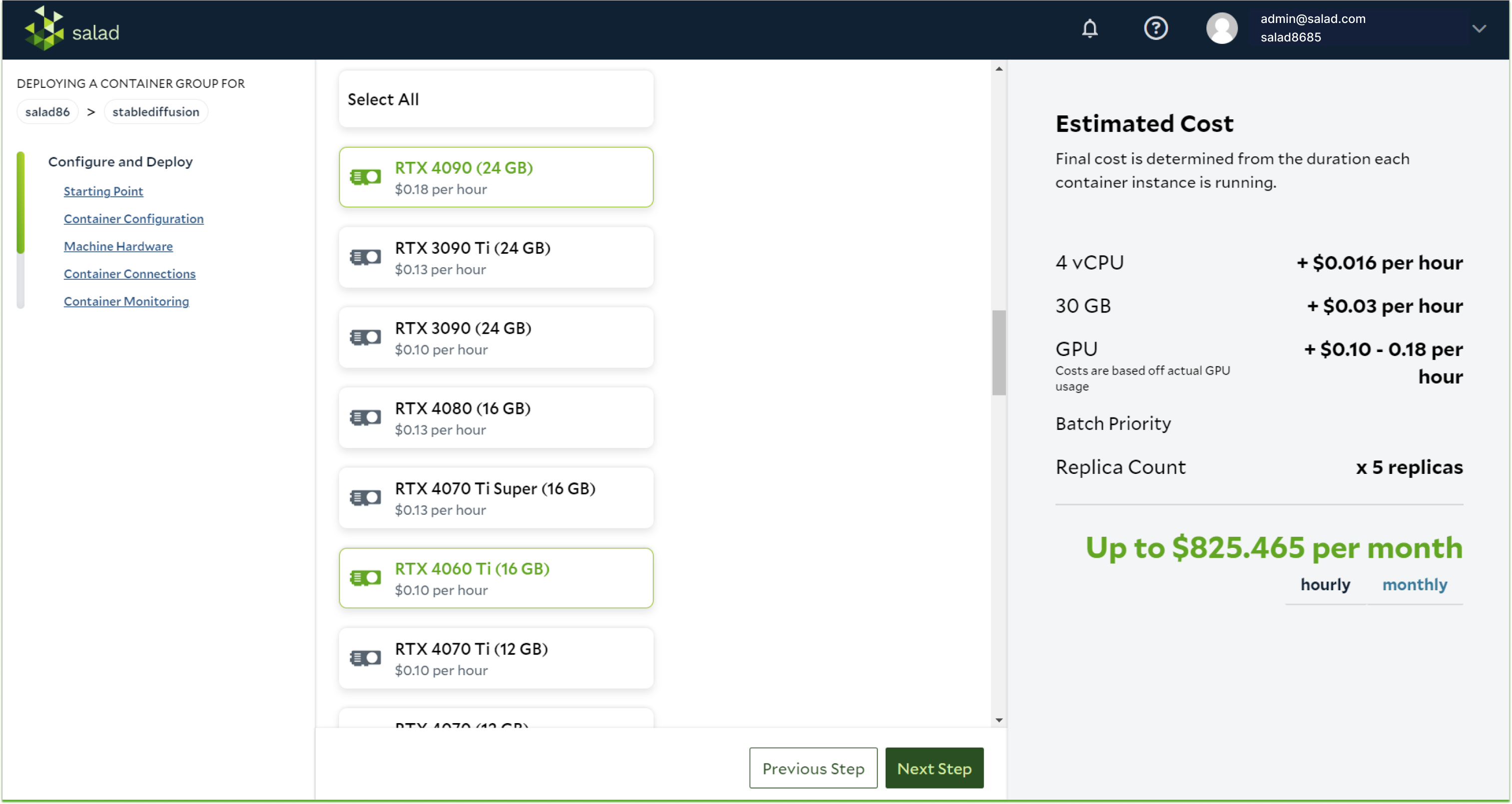
Scale quickly to thousands of GPU instances worldwide without the need to manage VMs or individual instances, all with a simple usage-based price structure.
Get more images per dollar than any other cloud
3405 images/$ for SDXL
4265 images/$ for Flux.1-Schnell