Every year, private industry overlooks hundreds of potentially groundbreaking scientific computing projects, either due to the upfront cost or uncertain prospects for profitability.
One of the most affected areas is what’s known as “fundamental research”—exactly the kind of rigorous theory testing required to better understand natural phenomena, but which usually doesn’t translate to short-term returns. That means the burden of advancing human progress often falls on the taxpayers through federal research grants.
Government science already runs on citizen dollars. If we ran it on citizen machines on a distributed cloud, we could conduct life-changing research and return some of the taxpayers’ hard-earned income.
The Compute-Industrial Complex
Whether they know it or not, taxpayers have always been instrumental to pushing the boundaries of science. Today’s most robust computer modeling is only made possible through public funds. Without these resources, scientists could never study climate change on a digital twin of the Earth, or simulate the young universe to grok the Big Bang.
Humanity owes a large part of its technological legacy to the continuous give-and-take between public sector research and private sector development. Entire multinational industries derive their lifeblood from scientific discoveries promulgated by the world’s governments. And though we may benefit from the resulting products and services, everyday people like you and me are footing the bill at both ends.
In government-administered computing projects, the burden on taxpayers is unnecessarily compounded by infrastructure; the bulk of public compute-assisted research funding goes to building the kinds of supercomputers necessary to actually do the work.
Supercomputing clusters are complex, individualized systems where the speed of data transfer is just as vital as the total processing power. Colocating and networking processing hardware together with high-throughput interconnects helps maintain the rate of data flow, but this introduces additional, often expensive considerations like cooling and redundant energy supplies. Traditional data centers also need to contend with the hardware upgrade lifecycle; without regular upgrades, many supercomputers become obsolete within five years.
Only a handful of companies (such as HPE or IBM) have access to both the expertise and the relationships with hardware suppliers required to design and build massive supercomputing infrastructure. Other renowned private enterprises may specialize in building these types of systems under contract, but neither their services nor the underlying hardware come cheap.
Citizen Science Isn’t New
Given the exponential pace of computer development, it makes sense that the majority of today’s fundamental research should incorporate sophisticated technology. But did you know that distributed networks of heterogeneous consumer hardware can act as cloud layers that are equally performant and more cost-effective than traditional data centers?
Consumer-supported computing allows individual users to connect their PCs to a distributed network in order to process discrete parts of a larger workload. With a well-architected system in place, anyone with a reasonably powerful computer1 and access to the Internet could support cutting-edge research like protein synthesis or climate modeling right from home.
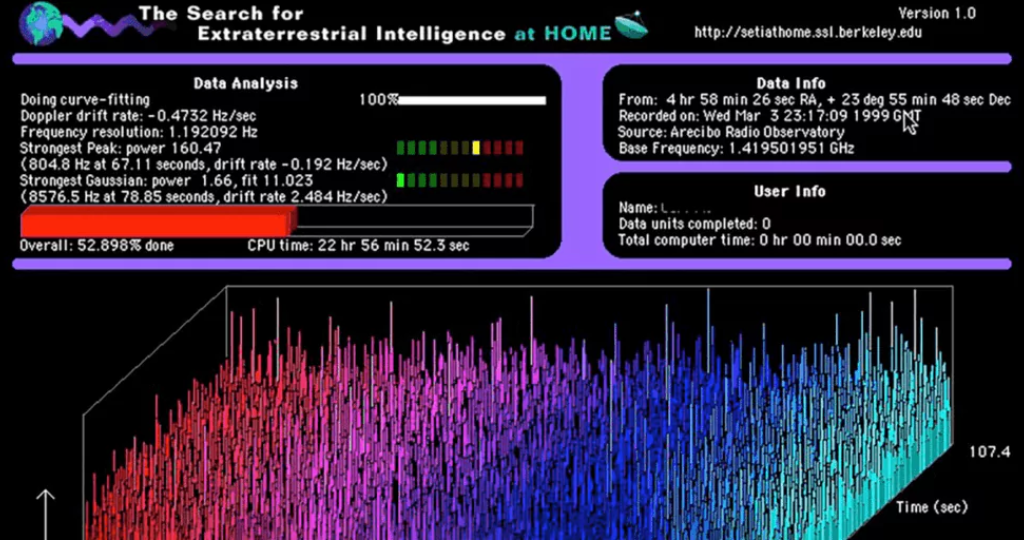
There are also good reasons to think that private citizens would be more than willing to do so. Do you recall seeing monitors in your school computer lab displaying colorful charts like these?

That was none other than SETI@home, a crowdsourced research application created by the Search for Extraterrestrial Intelligence (SETI) in hopes of identifying anomalous events that may originate from our intergalactic neighbors. With thousands of connected individuals lending processing power to SETI’s workloads, researchers were able to analyze a massive collection of radio wave emissions originally detected by the Arecibo and Green Bank radio telescopes.
SETI@home established one of the first successful implementations of consumer-supported distributed computing at scale. In March 2020, SETI shut down the project after 21 years of operation because it was too successful; network participants had processed such an overwhelming volume of data that astronomers would need years to cross-reference the results for signs of extraterrestrial life.
Following their example, researchers at Berkeley developed the Berkeley Open Infrastructure for Network Computing (BOINC) platform. BOINC permits academic researchers to upload programs and data as workloads for distributed processing on a consumer-supported network, where participants—private individuals running the BOINC desktop client on their personal computers—can voluntarily share resources with research that interests them.2
Since its founding, the BOINC platform has gone on to support SETI@home and a multitude of other fundamental research projects in various scientific fields. These projects have proven that consumer-supported, distributed networks can be leveraged for scientific applications.
With the right incentives to participate, I believe we can reduce the typical fundamental research budget to a trivial expense.
A Problem of Incentive
The world’s latent processing reserves are perfect for the types of government-administered, scientific research projects that usually require expensive supercomputers.3 Since the hardware has been purchased by private consumers, there are fewer concerns about budgeting for expensive upgrades simply to reach a current hardware generation or speed up your 3D-accelerated processing.
Distributed networks like BOINC and SETI@home demonstrated just how readily millions might choose to aid a scientific effort out of enthusiasm alone (an exciting data point for those managing research grants at the NSF, to say the least). All that’s left is networking those devices in a way that allows dynamic allocation of their shared resources—but accomplishing that requires solving a problem endemic to contemporary academic science.
How do you motivate enough participants to conduct the research?
Of hundreds of vital research projects listed on the BOINC platform at any given time, only a thankful few garner sufficient interest or processing supply to achieve their desired outcomes, while sexier projects—like curing COVID-19, or dialing up the nearest spacefaring civilization—attract supporters in droves. Far too often, high-profile workloads overshadow equally important research in niche fields that doesn’t make for a good headline.
When forced to compete for mindshare, scientists must effectively moonlight as marketers simply to conduct their research. But what if you could engage a whole nation of users with a modest incentive? At Salad Technologies, we’ve built a distributed cloud network based on a mutual reward model we call computesharing.
The Computesharing Model
Most fundamental research projects require public funds and private computing infrastructure, but the actual computations are done on processors identical to those found in consumer PCs.
Salad activates an underutilized supply of latent consumer compute resources on a globally geodistributed volunteer network. By rewarding our community participants with personally meaningful incentives—such as video games, gift cards, or streaming subscriptions—we’ve established a cloud computing platform that adheres to a principle of mutual benefit.
The most performant nodes on the Salad network are high-end gaming computers. As the entertainment industry consistently improves video game engines and graphics, passionate gamers reliably upgrade their hardware to enjoy the latest blockbuster titles. Believe it or not, the owners of the most powerful GPUs on the planet have a vested interest in eliminating the costly necessity of the hardware upgrade cycle. That fact alone makes rewards-driven computesharing networks the ideal venue to leverage surplus resources for scientific research.
With help from hundreds of thousands of active participants, our network has reached overall peaks of nearly 90 petaflops, which is enough raw calculation to rival some of the world’s fastest supercomputers. Our simple incentive model proves that computesharing communities can be built and maintained for around 1% of the cost for an equivalent supercomputing cluster, which could revolutionize the way we fund and conduct discrete fundamental research applications.
Consumer-supported computing networks like Salad can also be subdivided so that participants from a given nation could only process distributed workloads commissioned by their respective government. It’s one thing to hear that your representatives are funding an exciting scientific breakthrough, but it’s quite another to play a vital role in achieving it. Our users have consistently expressed interest in supporting all kinds of fundamental research projects for nominal rewards. Now it’s up to the policymakers to change their tune.
Redistribution for Real Work
Scientific opportunity lies in the gulf between curious volunteerism and costly compute. We can now build exascale computesharing networks that reward participants with tangible value for a fraction of the cost to build a conventional data center.
For research that requires massive amounts of reliable compute power, a system of tangible incentives provides performance guarantees that voluntary resource sharing simply cannot. Advanced scientific workloads require consistent uptime, obey tight deadlines, and—let’s face it—may fail to interest the average person without supplementary marketing.
Distributed platforms like BOINC have shown the world how to captivate the scientific curiosity of a lay populace for 21 years.4 Free and accessible compute resources have been a boon to scientists everywhere, particularly those with minimal budgets. We believe that incentivized computesharing networks could complement those important academic initiatives by providing affordable infrastructure for the hundreds of fundamental research projects that fail to find funding every year.
Scientists shouldn’t have to waste valuable resources on marketing their hypotheses, and academics shouldn’t have to find millions in funding to conduct a study. Unless we reconsider the way we approach scientific computing tasks, we’ll risk settling for hindered human progress at the continued expense of the middle class.
Hiring the infrastructure of a computesharing network does require a modest budget, but the price is well below the extravagant cost of building and maintaining a supercomputer—and a large part of that revenue is distributed back to the citizens powering the network.
Digital Civic Engagement
Taxpayers already pay to train some of the largest artificial intelligence models and run our most complex simulations. Now that more cost-effective and equally viable compute solutions are available, governments have a duty to at least consider them.
If government science is ultimately for the benefit of the citizenry—and they’re paying for it anyway—there should be no moral qualms with returning part of the expense to the people who make it possible. After all, it’s not only recompense for work performed, but a virtuous cycle that could stand to generate authentic interest in science for generations to come.
Computesharing could very well define civic engagement in the cloud age. When provisioned with an accessible outlet for interacting with and supporting research, tomorrow’s youth may grow up with an appreciation for science that inspires them to celebrate it for a lifetime.
- Minimum hardware specs vary by network and workload. A single-core CPU is sufficient for some basic computing applications. For other workloads, such as deep learning models, often require 3D-accelerated processing from GPU hardware. Bandwidth requirements and uptime percentage (the time that the machine is connected to the network) are also dependent on the use case.
- As of this writing, Einstein@home and World Community Grid are among the most popular projects on the BOINC network. For more info, please see the complete platform rankings.
- Containerization technology has ameliorated many of the security concerns with distributed workloads, but decentralized architecture naturally has limitations. Embarrassingly parallelizable workloads without strict data security requirements would make for an ideal case study.
- This calculation includes the operational years of SETI@home, which was first released to the public in 1999.


